Pipelines
De modo a aumentar a rapidez do processador podemos implementar uma técnica conhecida como pipelining. A ideia é manter cada parte do processador sempre ocupada, dividindo as instruções em fases sequenciais ou etapas, permitindo que estas possam ser processadas por cada unidade do processador em paralelo. Incorporando este método conseguimos obter um maior throughput mas a latência das instruções não muda visto que o tempo para executar uma instrução não é reduzido.
A Pipeline do MIPS tem 5 etapas (stages):
- IF: Instruction Fetch - a instrução é lida
- ID: Instruction Decode - leitura de registos involvidos
- EX: Execute - a operação aritemética é executada ou o endereço é calculado
- MEM: Memory - acesso à memória
- WB: Write-Back - escrever o resultado num registo
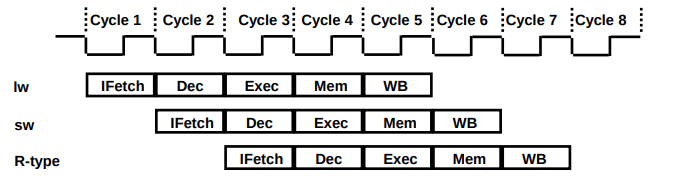
São mantidos registos entre os andares do pipeline, para controlo. A cada ciclo de relógio, a execução passa de um andar da pipeline para outro. Tal significa que o tempo de duração de um ciclo corresponde ao tempo de execução do andar mais lento. Por exemplo, se todas as etapas demorarem 200ps e a etapa de MEM tiver uma duração de 250ps, cada ciclo de relógio levaria 250ps. É de notar que caso não houvesse pipelining, cada ciclo de relógio corresponderia à soma da duração de todas as etapas, neste caso 1050ps.
Existe assim, uma redução susbstancial do tempo total de execução ao permitir a realização de várias instruções (com diferentes fases) simultaneamente. Assim que a pipeline estiver cheia, uma instrução é completada a cada ciclo, o que nos dá um CPI de 1. Se todas as etapas tiverem balanceadas, i.e. demorarem todas o mesmo tempo:
ISA do MIPS & Pipeline
O Instruction-Set Architecture (ISA) do MIPS foi desenhado para pipelining. Logo:
- Todas as instruções são de 32-bits - mais fácil fazer fetch e decode num ciclo.
- Existem poucos formatos de instrução - mais facil fazer decode e ler registos numa etapa.
- Apenas ocorrem operações de memória em Loads e Stores - podemos usar o passo de execução para calcular endereços de memória.
- Cada instrução escreve no máximo 1 resultado - nos últimos andares da pipeline (MEM ou WB)
- Operandos têm que estar alinhados em memória - uma transferência de dados leva apenas a um acesso à memória de dados
Problemas de Pipelining
Apesar das pipelines nos ajudarem imenso em termos de eficiência, existem situações em que o começo da próxima instrução no ciclo de relógio seguinte é impedido. A estas situações chamamos Pipeline Hazards e existem 3 tipos:
-
Structural Hazards: tentativa de 2 instruções diferentes usarem o mesmo recurso simultaneamente.
-
Data Hazards: a instrução seguinte depende do resultado da instrução anterior.
-
Control Hazards: uma decisão pode ser tomada antes da condição ter sido avaliada por uma instrução anterior (como acontece nos Branches).
Normalmente, estes problemas conseguem ser resolvidos através de stalls. A unidade de controlo da pipeline é responsável por detetar estes problemas e resolvê-los.
Structural Hazards
Quando há conflito no uso de um recurso. Por exemplo no caso da pipeline do MIPS com uma única memória: instruções Load/Store acedem a dados, pelo que o fetch da instrução deveria ter que usar um "stall" para esse ciclo.
Data Hazards
Uma instrução depende do acesso a dados realizado por uma instrucão anterior. Existem vários tipos de data hazards mas o mais abordado na cadeira é o RAW (Read After Write), onde uma instrução tenta ler um registo que ainda não foi escrito por outra anterior.
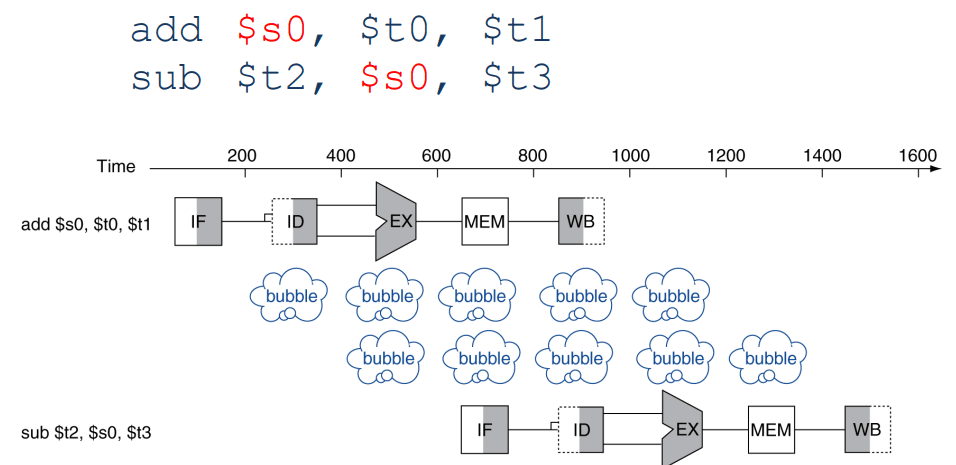
Como solucionar este problema?
Forwarding
Para resolver o problema das dependências de dados podemos usar o resultado assim que estiver disponível, não sendo necessário esperar que seja colocado num registo, através de ligações adicionais no datapath.
Olhemos para o seuinte exemplo:
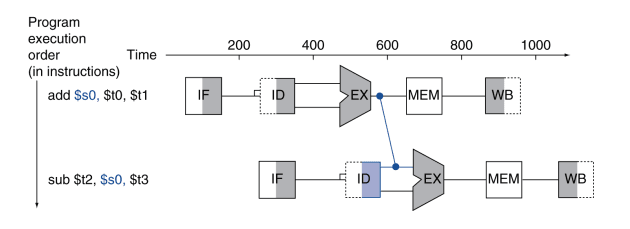
Na primeira instrução, o valor do registo $s0 irá ser determinado no andar EX, como em qualquer outra instrução aritmética. Se forwarding não fosse usado teriamos de esperar até que este valor fosse escrito no registo $s0, no andar WB, para que a segunda instrução podesse usar esse valor, o que nos obrigaria a usar stalls que degradariam a performance do CPU. Em vez disso podemos simplesmente propagar o valor (fazer forwarding) logo após este ser calculado, partilhando-o entre etapas.
É importante ter em conta que apesar de bastante útil, esta sofisticação pode não ser adequada em certos casos visto que não podemos fazer forwarding para ciclos que ocorreram anteriormente ao ciclo em que o valor foi calculado.
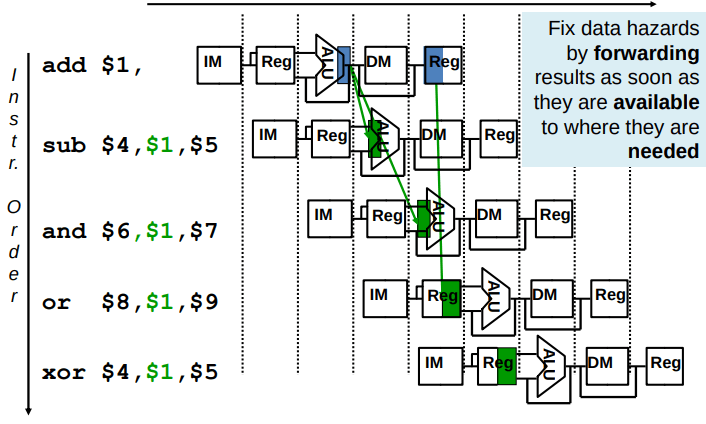
Exemplos
É recomendado a resolução da ficha prática de Pipelining para melhor compreensão do conceito de data forwading.
Control Hazards
Um branch determina o fluxo de controlo, sendo necessário esperar pelo seu resultado. Nem sempre o pipeline consegue fazer fetch da instrução correta. Existem varias soluções:
- Stalling: lento e forte impacto negativo no CPI
- Fazer a decisão o mais cedo possível no pipeline (reduzindo ciclos afetados por stall)
- Adiar a decisão (necessário apoio do compilador)
- Prever o resultado (e esperar que corra bem)
Delayed Branch
Se o branch hardware for movido para a etapa de ID, então é possível eliminar todos os branch stalls com delayed branches. Com esta técnica, executamos sempre a próxima instrução sequencial depois da instrução branch, sendo que o branch só é efetuado após essa instrução.
Com pipelines maiores, o branch delay começou a precisar de mais que um slot.
Branch Prediction
Fazer uma previsão do resultado do branch, apenas havendo um stall caso esta previsão esteja errada. No MIPS é possível prever que o branch não é feito, o que permite ir buscar a instrução a seguir ao branch sem delay. Caso, afinal, o branch seja efetuado, é necessário fazer flush das instruções que entretanto tinham sido entretanto feitas, i.e. substituí-las por um nop.
Static Branch Prediction
Os control hazards são rresolvidos assumindo sempre um dado resultado e procedendo sem esperar para ver o resultado final. Os dois tipos de Static Prediction mais comuns são:
Predict Branch Not Taken - assume-se sempre que o branch não é tomado (é feito flush caso seja tomado)
Predict Branch Taken - assume-se sempre que o branch é tomado (é feito flush se não for tomado)
Dynamic Branch Prediction
O hardware mede o comportamento do branch, tendo em conta o seu historial das últimas decisões. Assume que no futuro, o comportamento se vai manter, atualizando o historial quando estiver errado ou for necessário. Por outras palavras segue-se a moda.
Um mecanismo que incorpora esta ideia é o 2-Bit Predictor, que muda a sua escolha caso ocorram duas escolhas erradas sucessivas.
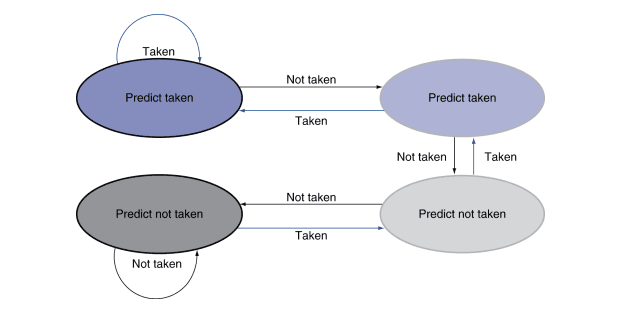
Exceções e Interrupções
Até agora vimos a utilidade do Pipelining e as diversas formas que temos de resolver dependências entre instruções. Mas é imperativo que quando surjam eventos inesperados na execução, estes sejam tratados pelo CPU. Estes eventos podem ser geralmente categorizados em duas categorias:
-
Exceção - evento gerado pelo CPU e por ser causado por um overflow, opcode inválido, erro de floating point, ...
-
Interrupção - eventos gerados por um controlador externo, como por exemplo um IO device.
No MIPS existe um coprocessador que lida com as exceções (Coprocessador de Controlo de Sistema):
-
Guarda o PC da instrução (Exception Program Counter). Na verdade guarda-se o PC incrementado mas o handler tem isto em conta.
-
Guarda a causa do problema num registo dedicado.
-
Salta para um handler genérico:
- Lê-se a causa.
- Chama-se outro handler (se existir). Se o problema for remediável, são feitas as correções necessárias e retorna-se ao EPC.
- Termina o programa, se não houver alternativa.
Caso surjam múltiplas exceções de uma só vez podemos resolvê-las por ordem cronológica ou podemos usar métodos mais complexos como completar as instruções desordenadamente, no caso de pipelines mais complexas. Todavia o uso de pipelines dificulta este processo.